[Stanford CS217]CUDA中矩阵乘法GEMM优化的最关键点:向量内积和向量外积分别取行和取列 |
您所在的位置:网站首页 › cuda gemm优化 › [Stanford CS217]CUDA中矩阵乘法GEMM优化的最关键点:向量内积和向量外积分别取行和取列 |
[Stanford CS217]CUDA中矩阵乘法GEMM优化的最关键点:向量内积和向量外积分别取行和取列
|
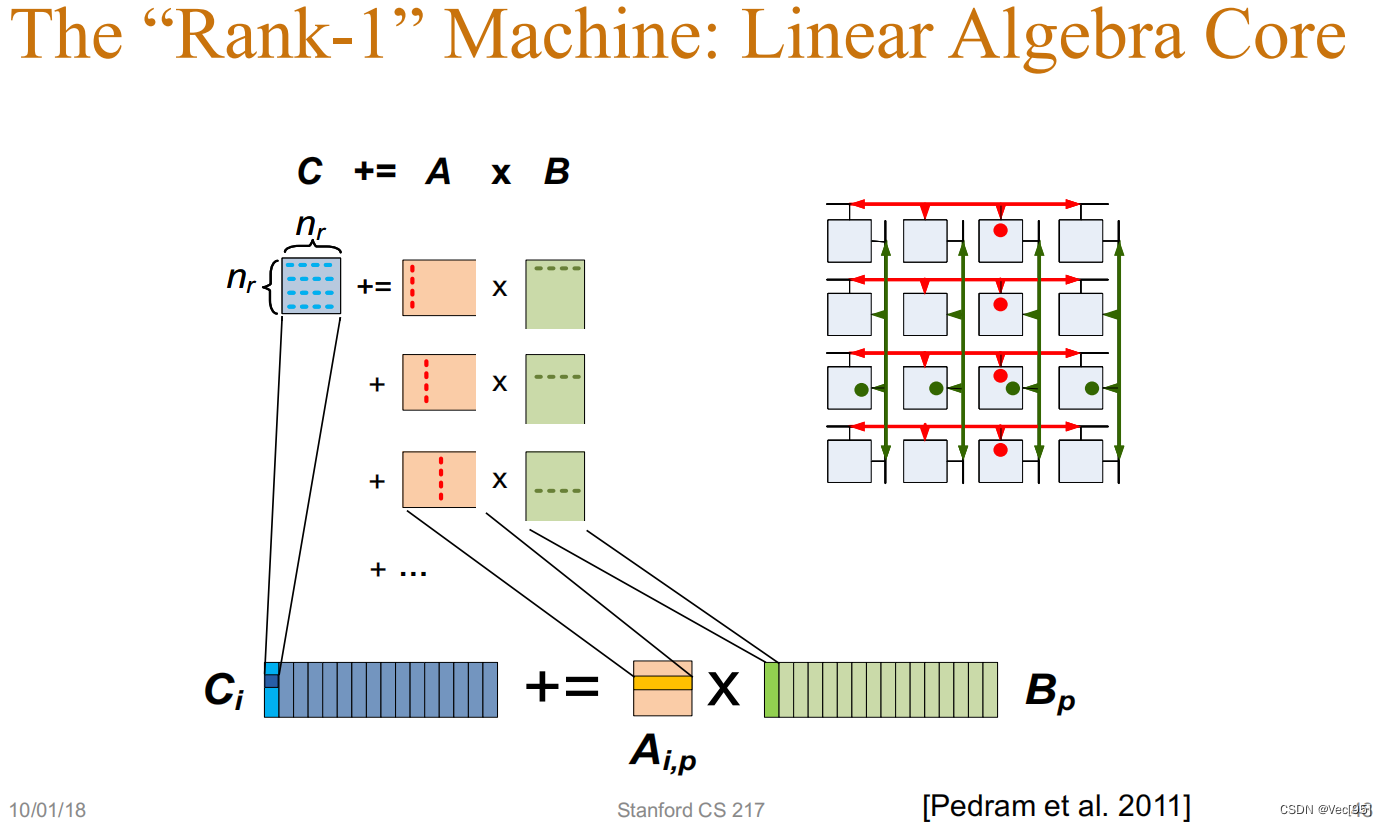
GEMM就是指计算 C=A∗B+C ,其中 A 、B和C都是矩阵,A是 M×K 的矩阵,B是 K×N 的矩阵, C是 M×N 的矩阵。 而最难以理解的就是向量内积方法取A的一行乘以B的一列,向量外积方法换成取A的一列乘以B的一行。 最基础的向量内积方法: 矩阵C中位于 (i,j) 的元素就是矩阵A的第 i 行和矩阵 B 的第 j 列,这两个 K 维向量的内积结果。 理想情况下性能应当受限于算术吞吐量,确切来说对于一个大型方阵,即 M=N=K ,矩阵乘法的数学操作复杂度为 O(N3) ,而数据量为 O(N2) ,同时计算强度为 N (这里的计算强度可以被理解为同一个数据被重复利用的次数)。 然而能够利用好理论计算强度要求重复使用每个元素 O(N) 次。不幸的是,为了重复利用元素,上述“内积”算法需要我们在片上高速缓存( 如NVIDIA设备中的Shared Memory)占据一大块空间,因此在 M 、 N 和 K 增大的时候无法实现。 for (int i = 0; i < M; ++i) for (int j = 0; j < N; ++j) for (int k = 0; k < K; ++k) C[i][j] += A[i][k] * B[k][j];而对于向量外积的矩阵乘法: 颠倒循环的嵌套顺序,即通过将最内层 K 次的循环提到最外层,取得好一些的性能。 这种实现在最外层的一次循环中只需要加载一次矩阵 A 的列和矩阵B的行,然后进行外层乘法计算并把结果累加到矩阵C中。在此之后矩阵A的这一列和矩阵B的这一行就再也不会用到了。 for (int m = 0; m < M; m += Mtile) // 沿着M维迭代 for (int n = 0; n < N; n += Ntile) // 沿着N维迭代 for (int k = 0; k < K; ++k) for (int i = 0; i < Mtile; ++i) // 计算一个tile for (int j = 0; j < Ntile; ++j) { int row = m + i; int col = n + j; C[row][col] += A[row][k] * B[k][col]; }在改变了这个思路之后,才有将全局内存中的A矩阵和B矩阵分别取一小块(tile)放入共享内存中进行FFMA操作,这时不加载A的一整列和B的一整行,而是按小块来加载A的列的一部分和B的行的一部分: 矩阵C分成若干 Mtile×Ntile 矩阵片(tile)来减小工作集的大小(之前说同一次最外层循环只加载一次矩阵A的列和矩阵B的行,假设加载的是A的第 k 整列及B的第 k 整行,这二者的计算实际上会在矩阵C中 M∗N 个元素中的每一个进行自加操作,因此这里提到“要求所有矩阵C中的 M×N 个元素都处于活动状态”,如果进行拆分成tile的话就不要一次读入整行整列)。注意每个tile都占用一个block进行计算。 我们对每个tile都执行外层乘法,因此有以下代码: for (int m = 0; m < M; m += Mtile) // 沿着M维迭代 for (int n = 0; n < N; n += Ntile) // 沿着N维迭代 for (int k = 0; k < K; ++k) for (int i = 0; i < Mtile; ++i) // 计算一个tile for (int j = 0; j < Ntile; ++j) { int row = m + i; int col = n + j; C[row][col] += A[row][k] * B[k][col]; }对于矩阵C中的每一个tile,矩阵A与矩阵B中的tile只需要读取一次,这样就可以达到 O(N) 的计算强度。矩阵C tile的大小的是依据L1缓存或是寄存器数量的上限决定的。这样外层的循环就能被简单的并行化了,这是个巨大的提升! 进一步的重构为利用局部性和并行性提供了更多的基础。我们可以通过在块中沿着维度 K 累加矩阵的积而不必只累加向量外层的积(Jie: 这里我理解还是在说拆分成tile执行累加免于一下子加载整个矩阵C)。我们常称此概念为矩阵乘法累加(accumulating matrix products, AMP)。 这就是向量内积和向量外积的最大区别。 使用更清晰的伪代码来表示: 该向量内积矩阵乘法的伪代码为: M=N=K=8; float a[M*K]; float b[N*K]; float c[M*N]; for i in range(M): for j in range(N): for k in range(K): c[i*N+j]+=a[i*K+k]*b[k*N+j];而使用共享内存和寄存器优化,基于向量外积的矩阵伪代码为: M=N=K=8; float a[M*K]; float b[N*K]; float c[M*N]; for k in range(K): for i in range(M): for j in range(N): c[i*N+j]+=a[i*K+k]*b[k*N+j];在向量外积中,编译器自动做了一些优化,将A从共享内存送入寄存器来进行计算: float a[M*K]; float b[N*K]; float c[M*N]; for k in range(K): regB[0:N] = b[k*N:(k+1)*N] for i in range(M): regA = a[i*K+k]; for j in range(N): c[i*N+j]+=regA*regB[j];
|
【本文地址】
今日新闻 |
推荐新闻 |